Goal
The goal with this short guide is to scrape while being signed in to a web page. I will for this guide use the GitHub webpage as it probably is familiar to most people reading this.
This approach does not work for all web pages, and every site’s authentication is different, but this might be a good start if you are trying this yourself.
Preparing the File
As mentioned, I will use Python for this, with the requests library. I will only focus on this in this guide.
Create a file, I’ll call it scrape.py for now. Install necessary requirements (well, only requests) and import it.
Installation
pip install requestsPython file
import requestsSession
We will use a Session object within the request to persist the user session. The session is later used to make the requests.
All cookies will then persist within the session for each forthcoming request. Meaning, if we sign in, the session will remember us and use that for all future requests we make.
# Create the Session Object
s = requests.Session()
# Example Request
response = s.get("www.google.com")Getting the Data We Need
Ok, so basically, we need to know what data to pass to which URL. This will be done within Chrome.
We need to know two things:
- The URL to which the
POSTrequest (sign in) will be sent - The payload, or data that will be sent.
Let’s just open the Developer tools, go to the Network tab and log in so we can catch the URL.
A tip is to go to the login URL, clear the network tab so all previous requests disappear, making your login request probably show up at the top.
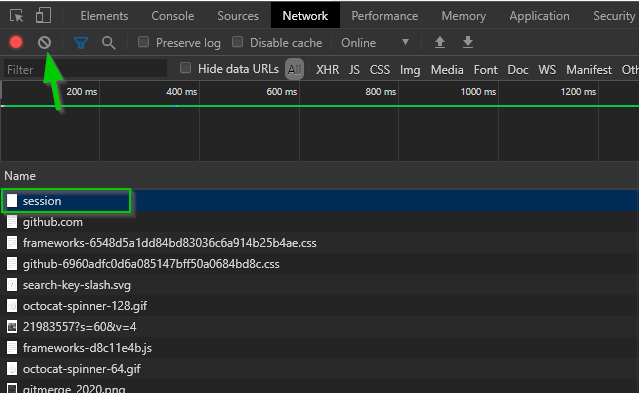
The arrow points at the clear button, while the square marks the login request. Click it to get information about it.
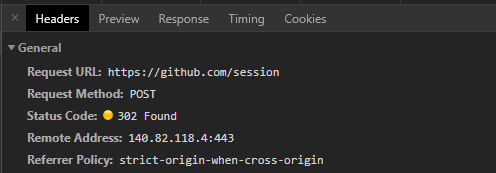
The URL is clearly shown to be https://github.com/session, so let’s save that. This is where our first request will go.
scrape.py
import requests
url = "https://github.com/session"
s = requests.Session()
response = s.post(url)This won’t work, because we are not sending the correct data. Let’s scroll down on the session request we caught before to see the data sent.
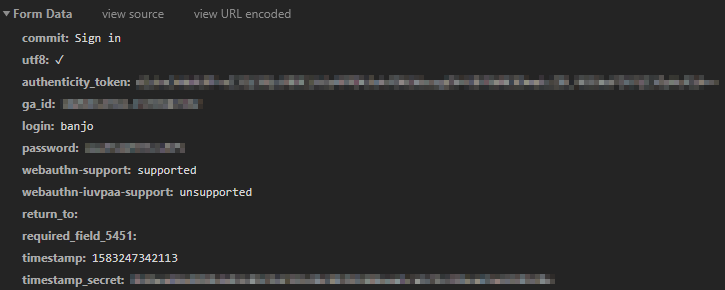
I did remove some of my personal data. But this is quite a lot of data we need to pass when making the request. There is, however, a great tool to use. You can access it here.
With this, you can just copy the request and get all the data necessary to make the request.
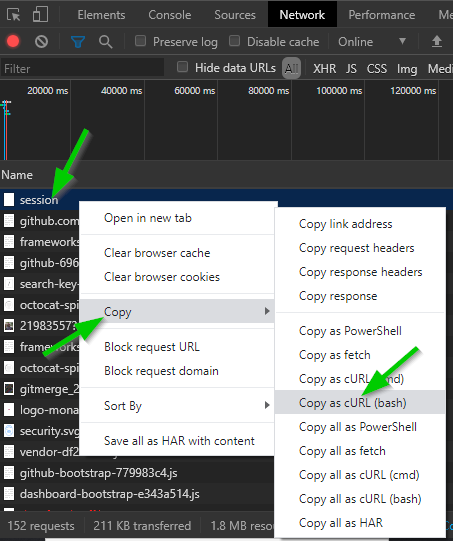
Copy the request data and paste it into the left field on the link. You’ll get a complete request with headers, cookies and all on the right side.
So we need two things, the cookies and the data. Let’s just paste those two into our python file. You could take the headers as well, but I won’t for now.
scrape.py
import requests
data = {
# ...
}
cookies = {
# ...
}
url = "https://github.com/session"
s = requests.Session()
response = s.post(url, data=data, cookies=cookies)So we basically just pass them into the request. We won’t do much with that response for now, so you don’t even need to save it to a variable if you don’t want to.
Now you are done with your first part. You have made the request to sign in. All other requests you make in the same script will be considered signed in.
Signed In
So now that we are signed in, we can, for example, make a request to a private repo. I’ll make a request to the repository of this specific blog, as it is private on my GitHub.
scrape.py
# ...
s = requests.Session()
s.post(url, data=data, cookies=cookies)
response = s.get("https://github.com/banjo/code")Scraping
So now, the actual scraping. This guide won’t cover that. But if you want, you can read my other guide on how to scrape with Beautiful Soup. It’s very easy to just pick up where you left off here.